
Share




Note: This is part one of a two-part series.
One of the foundations of testing is repeatability. If you can’t repeat a test and get similar results, you can’t trust the data.
And one of the main reasons for unrepeatable results? Outliers.
Even with proper test setup and statistical rigor behind confidence calculations, outliers can and will skew results, providing a false positive or negative. If you want to continue to advance your testing program, it’s imperative that you account for outliers.![]()
Back to basics: What’s an outlier?
An outlier is a data point that’s considered abnormal, typically seen in sample sets which have a heavy tailed distribution.
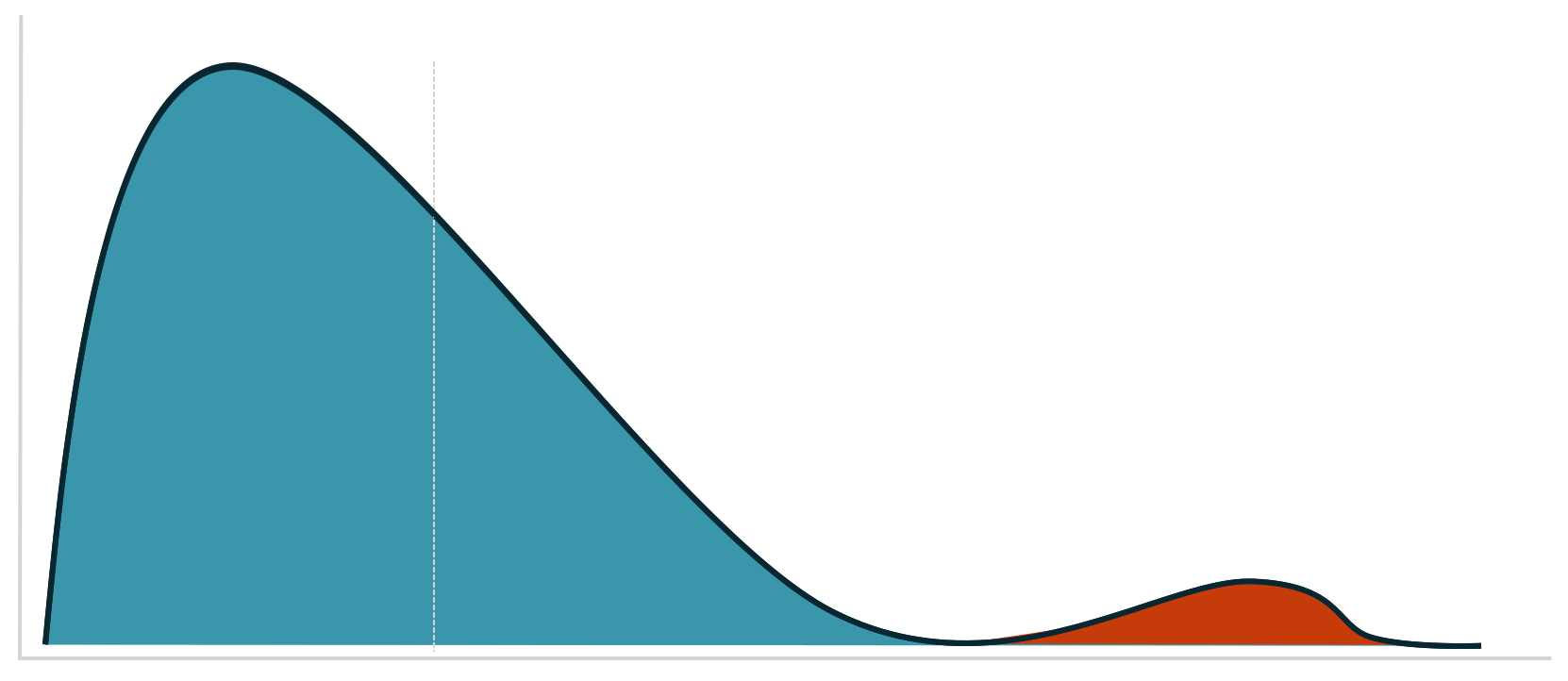
They can occur by chance or through measurement errors. In both scenarios, you need to define and deal with these data points.
In this article, I’ll discuss two key concepts of outliers:
- Why outliers are important
- Types of outliers
In part two, I’ll go over what you can do to fix them.
Why are outliers important?
If you want to gain support for testing, you need to earn stakeholders’ trust. And part of that comes from relying on sound data.
Unfortunately, outliers can drastically skew results, causing a test to be seen as a win when it’s a loss—or vice versa. Even one outlier can cause this effect if it’s extreme enough.
Here’s an example. In one of our previous retail tests, we saw a -3% lift via the testing tool upon initial analysis.
Then we examined the outliers, as we do for every test.
After employing outlier treatment techniques, the lift dramatically increased. It turned out to be a win.
If we hadn’t used all the treatment techniques I discuss in part two of this article, we would have concluded that the test was flat. That’s because conversion, visit, and visitor outliers were all present. (More on that in a moment.)
In this particular situation, resellers were the culprit—customers who buy in bulk with the intention of reselling items later. Far from your typical customer, they place unusually large orders, paying little attention to the experience they’re in.
It’s not just resellers who won’t be truly affected by your tests. Depending on your industry, it could be very loyal customers, in-store employees who order off the site, or another group that exhibits out-of-the-ordinary behavior.
Types of outliers
The types of outliers you’ll see depend on the data sets you have access to as well as the tools you’re using. In the optimization space, there are three main types:
- Conversion-level outliers – Individual conversion values that are considered abnormal. In the retail space, this would include units and revenue or a specific order.
- Visit-level outliers – Individual visits that are considered abnormal. Conversion examples include pageviews, form submissions, cart additions, orders, units, revenue, etc.
- Visitor-level outliers – Individual visitors that are considered abnormal. Conversion examples include visit frequency and visit numbers in addition to pageviews, form submissions, cart additions, orders, units, revenue, etc.
Stay tuned for part two of my outliers post, where I discuss how you can fix the outlier problem and get test results you can trust.
—
Brooks Bell helps top brands profit from A/B testing, through end-to-end testing, personalization, and optimization services. We work with clients to effectively leverage data, creating a better understanding of customer segments and leading to more relevant digital customer experiences while maximizing ROI for optimization programs. Find out more about our services.
Categories
Related Resources
Dynamic Research Integration: Unleashing the True Power of Insights

December 14, 2023


Can Web Behavior Predict COVID-19 Transmission?

October 21, 2020
Tips for Client-Side A/B Testing with AngularJS

October 5, 2020
Storytelling With Data

September 28, 2020