
Share




Part two of a two-part series.
In the first post of this series, I discussed the different types of outliers and why they’re important.
If you haven’t already, take a couple of minutes to read it now.
In this post, I’ll cover:
- Outlier treatment techniques
- Current techniques used by testing tools
- Additional techniques to employ
- Beyond the standard outlier treatment: What it looks like
- Fix outliers, build trust
Outlier treatment techniques
Outlier treatment is the process of removing or replacing conversions, visits, or visitors with a “normal” data point.
Removal involves eliminating the data point from the sample. Replacement involves swapping the data point for the mean or median of the sample.
Many resources describe when to remove and when to replace. The bottom line: in most cases, it’s recommended that you replace outlying conversion values and remove outlying visits and visitors.
This is because a singular conversion or a 1 or 0 cannot be determined as an outlier, but the value within that conversion can. This is similar to visits and visitors, which are made up of many actions that can be used to define data point.
Furthermore—and I’ll cover this in more detail later in the post—this removal/replacement becomes inherently dependent on the tool.
Types of treatment include:
Conversion-value level outlier treatment — treating individual mean conversions based on specified criteria.
The key here is mean conversions. Proportion-based conversions or simple 0s and 1s do not allow for outlier treatment at the conversion level, as there is not a measure of variability including range, variance, and standard deviation.
However, testing means allows for variance in the data at the conversion level. For example, a conversion value of 53.41 can be considered abnormal if a normal data point is below 40.00. Conversion-level outlier treatment would remove or replace the outlying conversion value.
Visit-level outlier treatment — treating individual visits based on proportion or mean conversions.
This goes one step further from conversion-level outlier treatment, allowing for treatment of outliers based on actions within a visit. What’s important here is the visits that are considered abnormal due to the actions placed within the visit.
Furthermore, if they’re allowed in the analytics tools, certain secondary metrics could be used to help define an outlying visit. For instance, you could conclude that 200+ cart additions in a visit is someone who would not be affected by a PDP test. Therefore, that visit may need to be excluded to garner a true read on the experience.
Visitor-level outlier treatment — treating individual visitors based on proportion or mean conversions.
Treatment based on a visitor’s “lifetime” actions is one of the most important—and overlooked—treatment types.
This is where you can define those visitor groups you feel are abnormal, whether that’s corporate employees, in-store employees, resellers, or just those visitors who convert at an abnormally high frequency. In any case, these are users who would not be affected by a test.
Using visitor-level outlier treatment for these groups is essential, because typical outlier treatment methods by order or visit may not detect their presence. In other words, a reseller who comes in every day and orders 100 items may not be caught by visit- or order-level outlier treatments, but he or she will be part of a visitor-level treatment technique.
Current techniques used by testing tools
Many testing tools currently have out-of-the box techniques to deal with outliers.
I’m not going to get into the specifics of each tool nor which is most accurate. However, I will say that many use a standard deviation-based outlier treatment. This is where a conversion is removed if its value is beyond a certain factor of the standard deviation of the data.
For example, if a mean conversion value of a sample is 53.41 and the standard deviation is 45.60, then certain tools would exclude 2.5 times the standard deviation over the mean. Thus a conversion value over 167.41 would be stripped from the sample.
Additional techniques to employ
Using a testing tool is not an incorrect way of dealing with outliers. In fact, there is a large amount of statistical rigor that goes into many of their calculations.
However, in order to increase confidence and trust in the data, I recommended performing additional outlier treatment.
Additional techniques can be beneficial when they focus on treating order-, visit- and visitor-level outliers. This is the main difference, and it’s something that most testing tools just inherently do not have the data to perform.
However, there are other major differences, such as a testing tool’s inability to calculate standard deviation exclusive of outliers and treating only the outliers that are true outliers to your business.
So how do you treat outliers beyond order level? The answer: with research and tooling.
First, most testing programs use analytics integration. This would be a requirement in most situations.
The next step is to figure out who your visitors are and what they do during visits.
It’s not as simple as analyzing a two-week stretch of a test. You need to figure out who your typical visitor is and how they use the site—not from a granular level of exactly which page they look at, but from a high-level visit and conversion level.
What works well in most situations is obtaining a year sample. This data set should be broken out by visitor and visit in addition to conversion.
Once you have the data set, your outlier determination should use statistically sound techniques to determine what your business considers an outlier. This may involve plotting the data and trimming prior to standard deviation treatment, in addition to consulting with stakeholders to determine if a user’s actions resemble a loyal customer, reseller, or other excluded group.
Beyond the standard outlier treatment: What it looks like
Take retail, for example. You should first analyze visitors, visits, cart additions, order, units, and revenue.
From there, it’s figuring out what threshold should be considered an outlier.
Is it a visitor who purchases $20K+ during that year sample? A visitor who has 50+ visits? A visit where 60+ cart additions occur … along with combinations of all?
These all need to be defined in the analytics tool and segmented out within the tool—while taking into account internal traffic, including in-store employees, and corporate traffic.
Here’s an example of proper analytics tool outlier segmentation from Adobe Analytics, based on one year range, and assuming a 3x stdev of each metric:
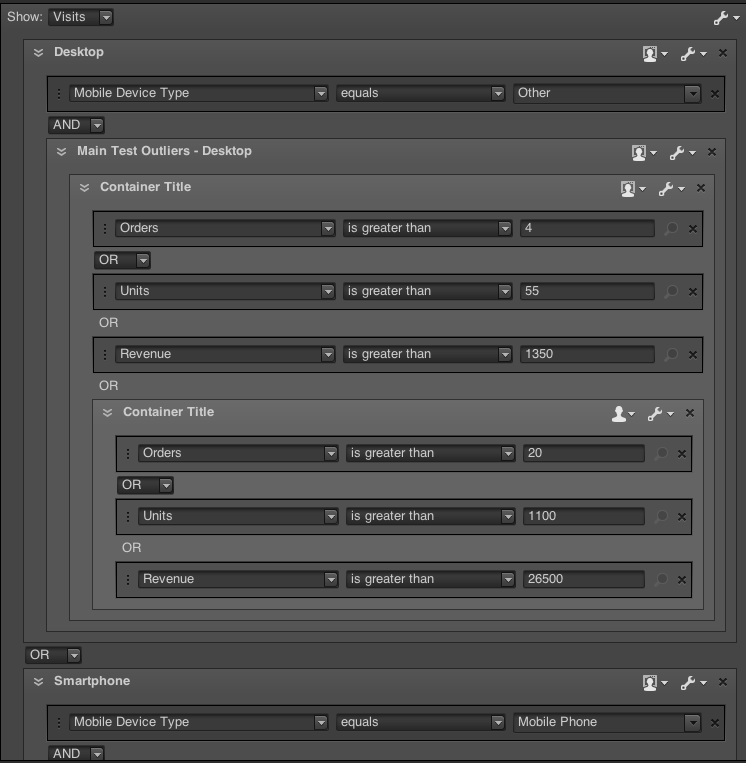
Once you’ve segmented the visitor and visits, the output of the sample will be much more accurate.
However, you’re still dealing with data that is excluded based on an aggregate site usage. Thus, excluding or replacing orders is imperative if you want to obtain the true read on the data. To do this, you should follow sound statistical practices, utilizing order by order data.
Fix outliers, build trust
If you want to increase rigor in your analysis, you must treat outliers. But that’s not enough. To build trust, you must fully explain why you are using outlier treatments.
In many cases, some stakeholders have access to testing tool results. If final reporting shows a different outcome, this can cause confusion.
This isn’t necessarily a bad situation, as you can use it to show the value of proper analytics.
Doing a bit of initial analysis on a site’s user base is a good first step in bridging this gap. Most of those involved in a site will understand the presence of outliers, but not the extent to which they can and likely are affecting data.
Showing a histogram of revenue by visitor or order value can help visually convey the idea. In addition, what percentage of revenue does your highest 1% group make up?
After you share the initial analysis, continue to bring attention to outlier treatment and remind everyone of outliers’ impact.
Outliers can be a significant challenge to understanding your data. But if you use these steps, you’ll increase trust and support for your testing program. At Brooks Bell, we go through this process in every test we report on, and constantly see the impact it makes.

This post was written by Brooks Bell Senior Optimization Analyst Taylor Wilson.
—
Brooks Bell helps top brands profit from A/B testing, through end-to-end testing, personalization, and optimization services. We work with clients to effectively leverage data, creating a better understanding of customer segments and leading to more relevant digital customer experiences while maximizing ROI for optimization programs. Find out more about our services.
Categories
Related Resources
Dynamic Research Integration: Unleashing the True Power of Insights

December 14, 2023


Can Web Behavior Predict COVID-19 Transmission?

October 21, 2020
Tips for Client-Side A/B Testing with AngularJS

October 5, 2020
Storytelling With Data

September 28, 2020